An implementation of Sparse Autoencoders to find highly interpretable features in GPT-2


Photo by Andrea De Santis on Unsplash
This article is my implementation of the methodology presented in Hoagy Cunningham et al. Sparse Autoencoders Find Highly Interpretable Features in the Language Models, 2023. A major problem hindering us from understanding the internal workings of a neural network is polysemanticity (which is when individual neurons in a neural network activate in different unrelated contexts), and the paper proposes that superposition (where the LLM represents more features than they have neurons for) is a cause. We can use sparse autoencoders (SAEs) to reconstruct the internal activations of an LLM. The paper shows how we can identify the components responsible for a language model’s behavior on tasks like indirect object identification.
This implementation aims to verify SAE's claims to extract monosemantic and interpretable features from the hidden activations of GPT-2 on the Open Web Text dataset, thereby making the internal representations more understandable.
Implementation strategy
The main idea behind this implementation is to use SAEs to break down complex and most likely polysematic activations of a pre-trained language model into a set of simpler, specific features. This helps in achieving monosemanticity, thereby making the internal representations more understandable.
Data: OpenWebText dataset
LLM: GPT-2
Experiment setup
Hyperparameters
dataset_samples: 20,000
layer_idx: 6
expansion_factor: 8
sparsity_coeff: 1e-3
batch_size: 512
lr: 1e-3
epochs: 100
max_length: 128 (
model_name: gpt2
mae_batch_size: 32 (57 texts and 640,000 tokens for MAE analysis)
num_mae_examples: 5.
mae_dataset_sample_size: 5000.
Optimizer:
optimizer = torch.optim.Adam(sae.parameters(), lr=config['lr']) -
Hardware:
NVIDIA RTX 4090 80GB
Architecture
Encoder: This layer maps the input activations to a sparse hidden representation
h=ReLU(Wenc⋅x+benc)
ReLU enforces non-negativity and sparsity
Decoder: This layer simply reconstructs the initial activations from the sparse hidden representation.
xrecon=Wdec⋅h+bdec
Loss Function
Reconstruction loss: L_recon = ||x - x_recon||²
Sparsity penalty: L_sparse = λ * ||h||₁
Total loss: L = L_recon + L_sparse
self.encoder = nn.Linear(input_dim, self.hidden_dim)
h = F.relu(self.encoder(x))
self.decoder_bias = nn.Parameter(torch.zeros(input_dim))
x_recon = F.linear(h, self.encoder.weight.t(), self.decoder_bias)
The architecture is made of an encoder (a linear layer followed by a ReLU activation) that converts high-dimensional model activations to a higher-dimensional sparse representation and the decoder (a linear layer using the transpose of the encoder’s weight matrix) that reconstructs back to the original activations from the sparse representation.
The loss function defines the training objective and is a combination of reconstruction loss, which is measured by the ) between the LLM’s activation and the SAE’s reconstructed output, and the sparsity loss, which is measured by the L1 norm of the hidden layer activation. The final component is the overcompleteness, which is the SAE’s hidden layer dimension and is set to be a multiple of the input dimension, which allows the model to learn more features than the original dimensions, thereby increasing the chances of finding distinct monosematic features. I will be logging the results of this experiment to Weights & Biases.
Workflow
Data Collection
The DataManager class handles the loading of the openwebtext datasets and has an alternative of using a dummy dataset if the data loading fails.
Activations Extraction
I used the GPT2ActivationExtractor to obtain the hidden state activations from the 6th layer of the pre-trained GPT-2 model. This is accomplished by tokenizing the input texts, feeding them through GPT-2, and capturing the activations.
SAE Training
The extracted activations were used to train the SimpleSAE model, and then the activations were split into training and validation sets and iterated through 100 epochs, and the parameters were optimized using the defined loss functions and trained successfully. Here is the configuration for the SAE training.
LLM Layer for Activations: Hidden state from the 6th layer of GPT-2.
SAE Overcompleteness: The hidden layer dimension was set to 8X the input dimension
Loss Function Hyperparameters:
Sparsity penalty (λ): 1×10−3
Optimizer: Adam optimizer with a learning rate of 1×10−3.
Training Parameters:
Batch size: 512
Number of epochs: 100
Tokenizer max_length: 128
Data for SAE Training: A sample of 20,000 text examples from the OpenWebText dataset.
Feature Analysis Data: For the Maximum Activating Examples (MAE) analysis, a sample text was processed. Each feature's top 5 activating examples are displayed.
Feature Analysis (MAE Analysis)
For each feature in the SAE’s hidden layer, we want to identify and display the text segments that cause that feature to activate strongly to understand the interpretability of the learned feature. For the MAE, I processed 157 texts and 640,000 tokens and then displayed the MAE for the top 20 active features.
Results
Now let’s look into SAE to see what each of its learned components is sensitive to. We have the feature ID, which represents each feature in the SAE, the total number of activations, the top activating examples, and their activation value. I have shared a sample of the top 5 below.
Learned feature analysis
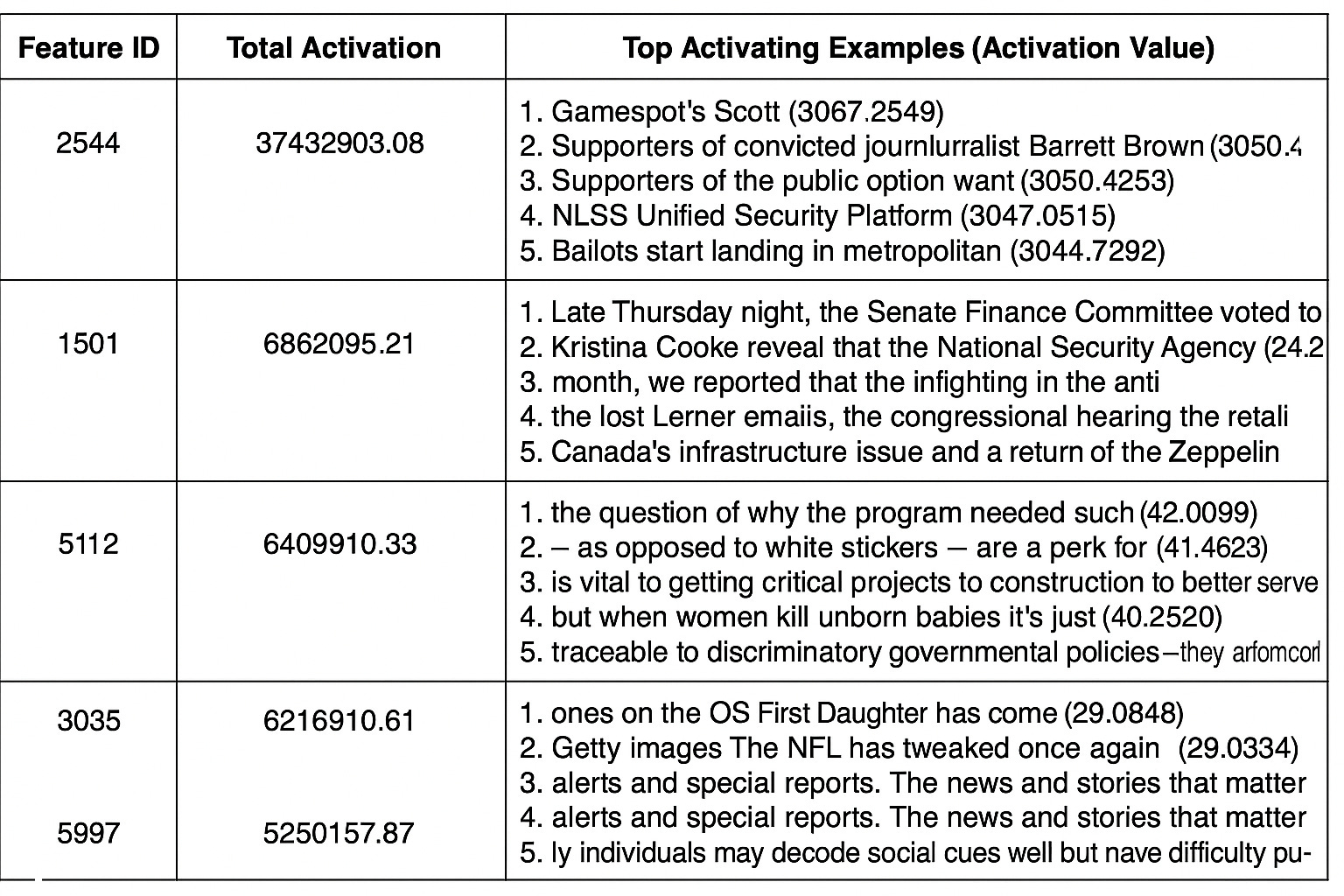
For feature 2344, it has a high total activation, which suggests that it is important, and judging by the activating example, it seems to be activating for nouns or particular entities.
Training performance
Here are charts from the successful SAE run where it is learning to reconstruct the activation while maintaining sparsity.
Validation Loss
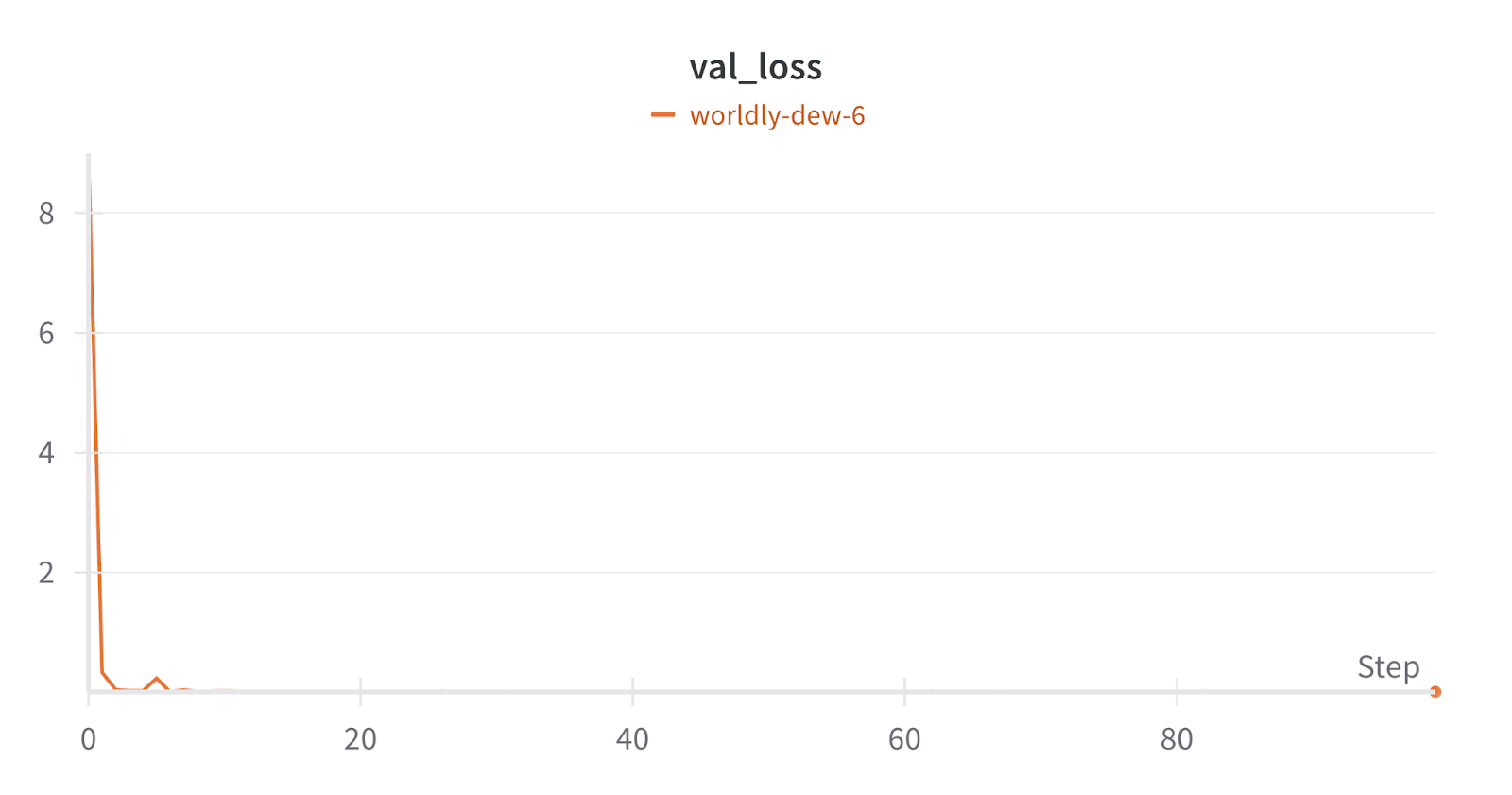
This is a combination of accurate reconstruction and sparsity, and from our trend, it is decreasing, which is good.
Sparsity
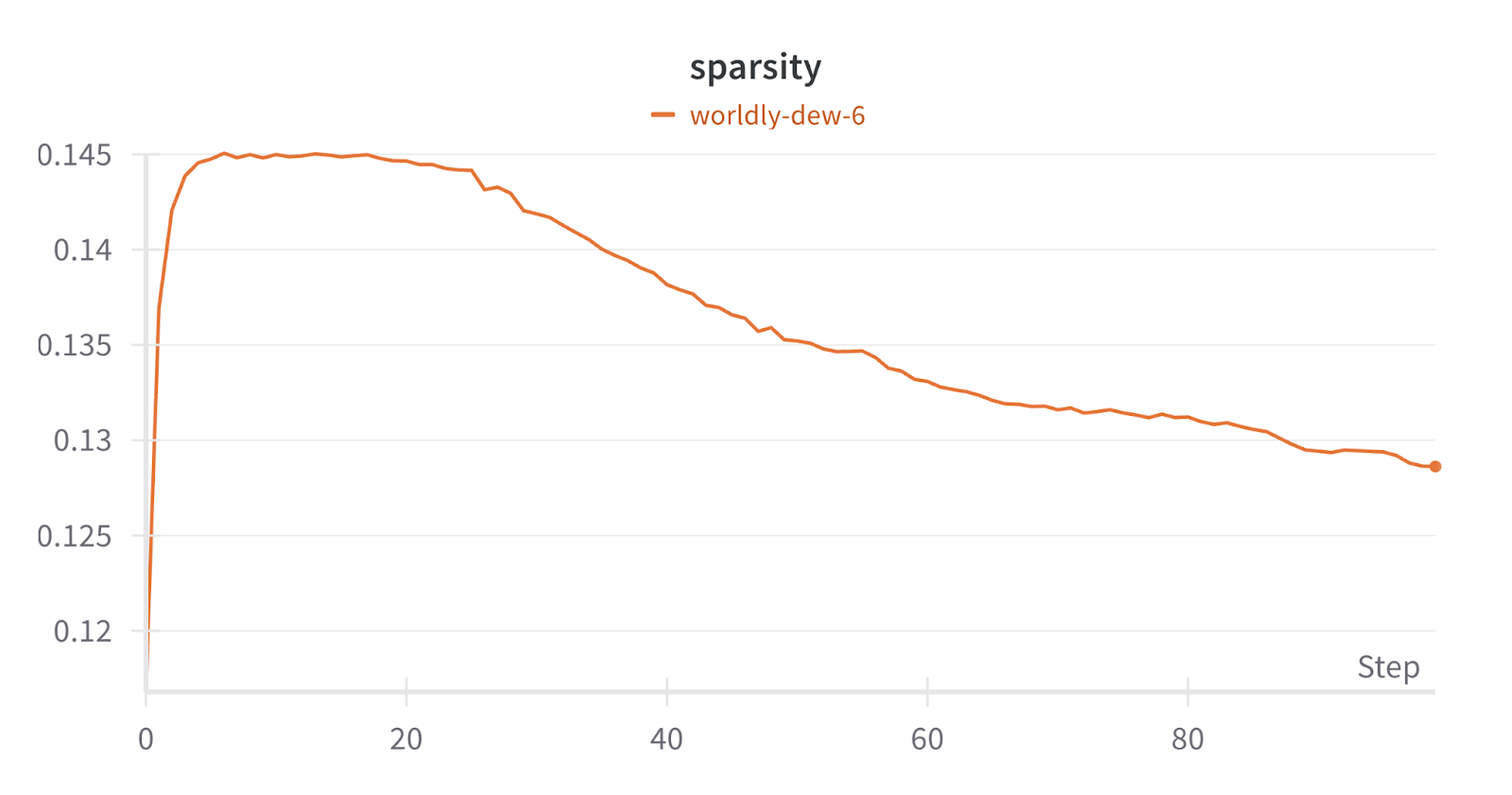
This metric shows how the sparse features are learned, aiming for a small fraction of active neurons. It seems to decrease and stabilize at a low value (around 0.125), which is expected from an SAE enforcing sparsity.
Reconstruction loss
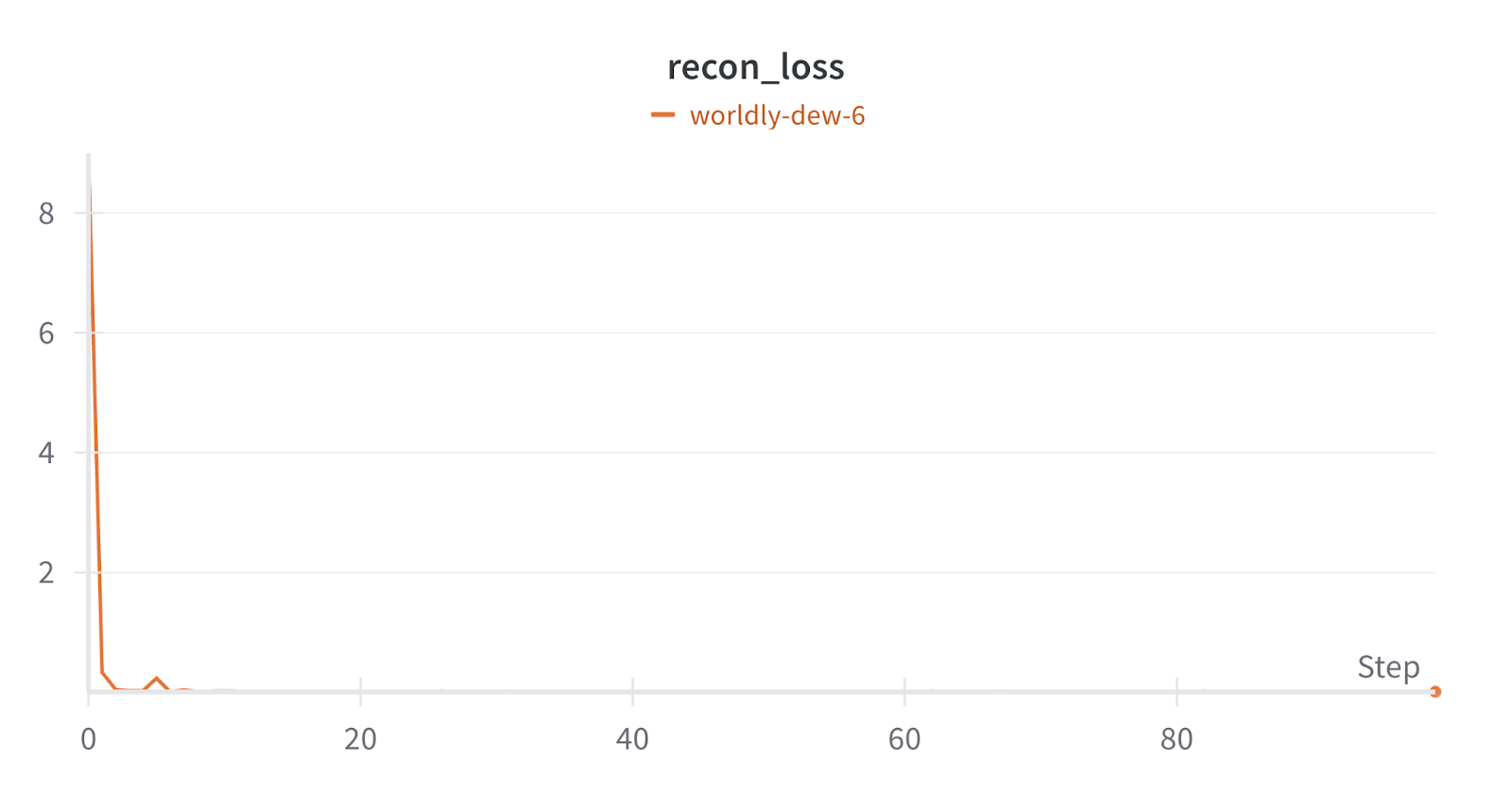
This tells how well the SAE compresses and decompresses the GPT-s activations without losing too much information, and it is also decreasing, which implies that the SAE learned to reconstruct the activations well.
Epoch
The epoch chart shows the training progress up to 100 epochs, allowing me to see the full training trend.
Conclusion
Implementing this paper was exciting and a learning curve, and you can try out more advanced feature interpretability techniques beyond MAEs. Working on this has significantly improved my knowledge and interest in mechanistic interpretation and given me an idea and direction for my project. Here is the link to a GitHub repo with the script.